I first applied Role Based Access Control, known colloquially as RBAC in the data engineering world, in my very 1st post-grad client engagement. As an associate consultant who was mainly doing grunt work, I jumped at the chance to review the database architecture of the solution we were building. The user permissions I discovered were built upon individual permission management, which becomes exponentially more expensive as a project scales, requiring multiple rows to define what a single user can access. While I wasn’t aware of RBAC as a formal concept at that time, my proposed solution was rooted in the foundational principles and value propositions of controlling access to resources through a meticulously curated role.
RBAC was formalized in 1992 by David Ferraiolo and Rick Kuhn, 46 years after the birth of ENIAC, modern computers' closest ancestor. As computers rapidly became more and more complex, the governing principles of how to manage their capabilities needed to evolve alongside them. At its’ core, RBAC is an amalgamation of tech bros' favorite buzzwords…”data governance”, “data privacy”, "principle of least privilege", etc. , which are all different concepts to describe the same overarching idea. Sophisticated & powerful databases need robust frameworks to enable effective interactions.
A well-architected database is rigorously designed to account for the needs of every potential user. Thus, defining access on an individual basis is a reflection of poor foundational planning. It's far more logical to define the database around roles than to try and build a role-agnostic database, because assigning individuals to the roles that best fit their use case & skillset is how the database runs smoother.
which came first, the role or the system?
My belief in this role-first approach transcends beyond database architecture, it's a principle that I apply to systems in general. As I reflected upon potential points in my life where this philosophy sprouted, I realized that my fascination with roles is almost certainly because I attended International Baccalaureate public schools throughout the entirety of my K-12 schooling. My pre-collegiate years were heavily project-focused, which exposed me to role delegation early and often. The entire curriculum was built around the "IB Learner Profiles", a distribution of learning aspects that was used to encourage students to be holistic learners, embodying shades of each individual profile in our own learning style.
i wanted that knowledgeable certificate more than anything
This heuristic of contextualizing learning and team building within nebulous archetypes has been a large part of my approach to the NBA draft. While I've refined my philosophy a great deal in a year's time, the portion below largely still remains my personal North Star.
"My draft philosophy is centered around quantifying, contextualizing and understanding a prospect's playstyle. My goal is to understand not just how a prospect functions, but why they function the way they do. When I uncover statistical red flags in a prospect's profile (negative AST/TO ratio, low rim frequency, low stock%, etc.), garnering an understanding of their role, team context and playstyle is my first priority, as it allows me to determine which problems are true limitations. Contextualizing players within roles also assists me in projecting their NBA outcomes, as certain playstyles have a lower threshold to attain rotation-level impact AND a prospect's ability to function within a variety of different playstyles, roles & contexts makes me more confident in projecting them as a quality NBA player. The tiers below are used to clearly define the line for returning at minimum rotation-level value:"
At the time that I wrote this, I was assigning roles using labels that felt intuitive relative to my understanding of the game, but I had no visibility into the statistical processes that went into how Bball Index assigned such roles. I also felt uneasy in the robustness of making deterministic assignments of player archetypes, as I was essentially presenting a very narrow path forward for each prospect, when each of them had varying degrees of adherence to the role I tagged. A key advantage of RBAC is that users' can stack roles, simultaneously existing as both an analyst and an engineer. Exhibiting the Principled profile while also embodying the Knowledge profile. Projecting as an Offensive Engine while maintaining shades of being a Connective Shooter. The framework needed to match the awesome complexity of projecting basketball development.
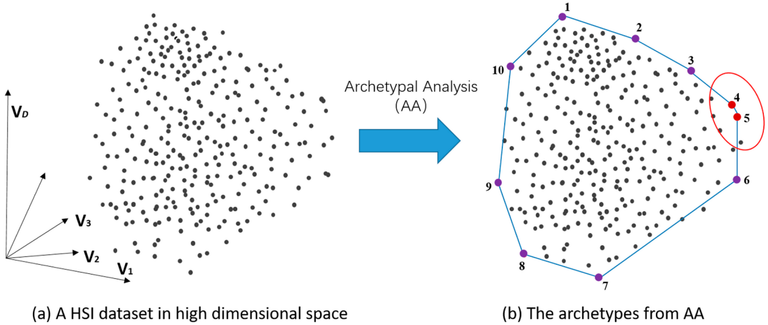
Similarity Defined by Distances from Contrasting Ideals
I'll save all the in-depth nerd jargon for the end of this piece, though it's worth briefly touching on how I opted to use archetypoid analysis[1] to classify prospects.
Some helpful definitions as I walk through my process:
Clustering: an unsupervised machine learning algorithm that organizes and classifies different objects, data points, or observations into groups or clusters
Centroid: the central point or arithmetic average of a group of data points, you can think of it as the average stats that of the players assigned to that group
Measures of distance: mathematical functions used to quantify how similar or dissimilar two objects are based on their features
Clustering is a massive umbrella that encompasses many different algorithms that all use varying measures of distance to answer the same question: how similar is this subset of data? These are commonly used to perform sentiment analysis, customer segmentation[2] and image classification[3]. This was the data classification method I was most familiar with, but the outputs are extremely deterministic and they have a tendency to either ignore outliers or pull them into clusters they really don't belong to. The vast majority of these algorithms would have replicated the rigid output I was already doing manually.
Because I wanted to model archetypes multidimensionally, I considered using some of the clustering algorithms that can output probabilities a data point is in a # of clusters, though I wasn't able to find much public work specific to sports and these algorithms don't quite reflect just how multifaceted the majority of basketball players are. Basketball is the one major sport that truly ebbs and flows, both in style of play and responsibility and players regularly exhibit qualities of several different roles in the course of a single game and even more so over an entire season.
A few months ago, Jack Blasberg posted some posters from the Sloan Sports Analytics conference. The poster in the bottom right corner caught my eye, as it seemed like it could be the exact type of approach I was looking for.
No @SloanSportsConf is complete without a tour of the research papers.
Some of the topics that caught my eye were automated officiating (a theme…), role based player evaluation, competitive balance design, and quantifying managerial impact. Check out the posters below👇 pic.twitter.com/2Y5fj8V25H
This paper from Clutch Data introduced me to archetypoid analysis (ADA), an unsupervised machine learning algorithm that seeks out the extreme points in a dataset instead of finding the most similar, while still outputting representative probabilistic distributions of basketball archetypes. Their work applying ADA to the NBA was the example I needed to build proxies to classify collegiate playstyles, as the explicit NBA quality playstyle data does not exist in a manipulable state for college basketball.
The 8 offensive stats that were deemed worthy enough[4]to classify the below archetypes:
Shot Profile Difficulty: difference between league average true shooting% and the player's expected true shooting% based on their shot profile
Defining Traits: High Defensive Rebounding & Size, Low Steals
2026 Prospects: Trey Kaufman-Renn (Purdue) 75.5% │ Jaxon Kohler (Michigan State) 74.7% │ Baba Miller (Cincinnati) 74.4%
Historical Example: Kevin Durant
Interpretability, Takeaways and Learnings
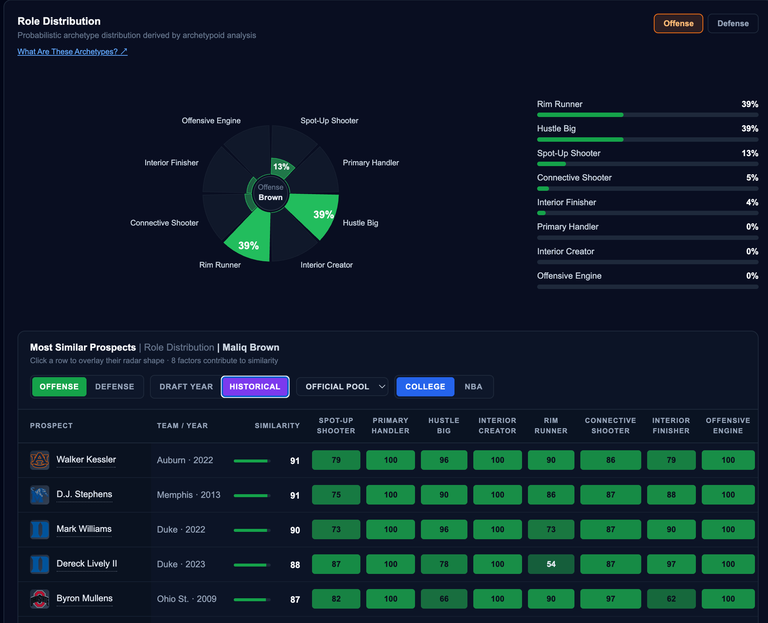
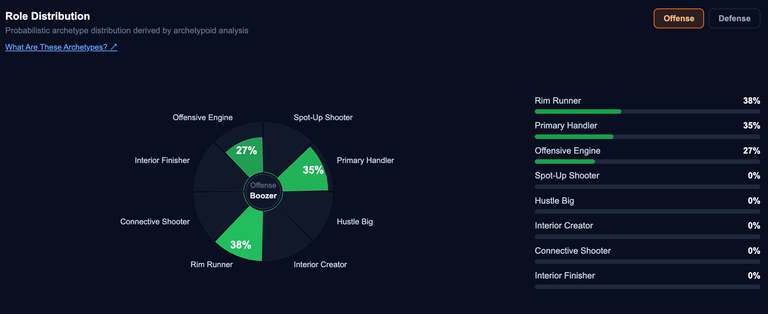
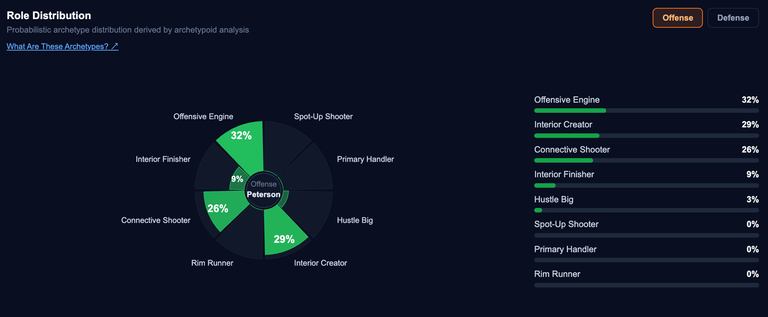
In his own philosophy article, Jason stated that "the pursuit of new and the pursuit of correctness go hand-in-hand." Introducing these novel archetypes into my evaluation framework has quantified many of my opinions on this draft class and about prospect evaluation as a whole. For instance, my love for malleable prospects is modeled glowingly by Cam Boozer and Darryn Peterson.
Cam Boozer's role distributionDarryn Peterson's Role Distribution
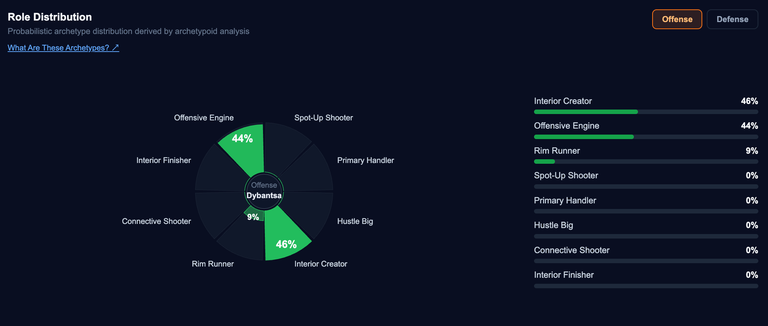
Dybantsa's role distribution however, echoes Ahmed's assertion that he:
"may be the most acute representation of one player transforming the complexion of a team’s playstyle of any prospect in recent memory." - from Draft Notes: AJ Dybantsa
Dybantsa's role distribution
In today's NBA, where everyone can legitimately do a little bit of everything, where bigs can initiate offense, wings are running high PNR and guards are playing out of the dunkers' spot, role malleability, even from a primary offensive player, is absolutely paramount. The tradeoff of platforming a player with a very narrow optimal role distribution reduces the capability of more holistic players to be able to contribute, which depending on the overall impact of that aforementioned hyper-specialized player, could bottleneck the overall efficacy of the team.
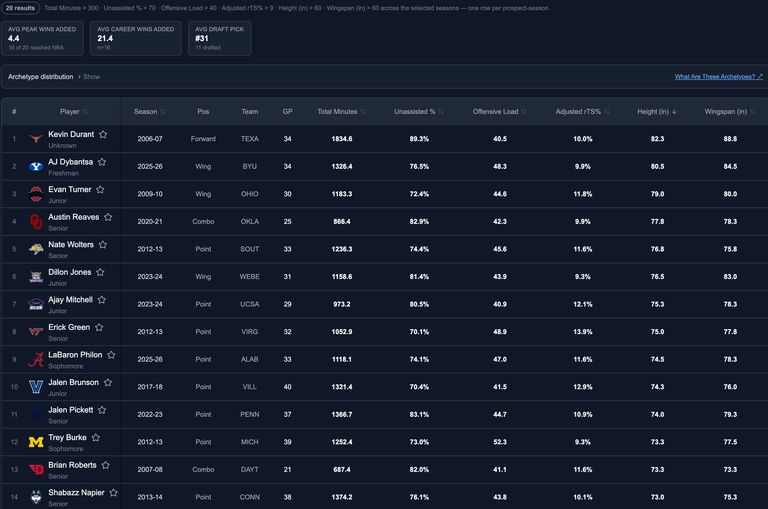
Dybantsa boasts one of the most impressive self-created seasons we've ever seen. 76.5% of his baskets were unassisted, ranking in the 95th%ile historically. He has a bonkers adjusted rTS% of 9.9% (95th%ile) with a 48.3 offensive load (99th%ile). There are just 24 prospects in my database who clear his 90th+%ile rankings as a load-bearing scorer. He rubs shoulders with the 2026 finals MVP, one of the greatest scorers ever, his fellow 2026 draft class mates Christian Anderson & Labaron Philon and 2 absolute gems in the 2nd round, Austin Reaves & Ajay Mitchell. The average height among these nuclear shot creators, is just 6'2. Dybantsa measured a full 6 inches taller.
Table sorted by height
That is the incredibly enticing AJ Dybantsa sell. This is the biggest, most effective, load-bearing offensive usage sponge freshman prospect we've seen since Kevin Durant. And yet, despite the unbelievably overwhelming scoring indicators, Dybantsa's scoring process is also reminiscent of some of the biggest false primaries in NBA history.
AJ Dybantsa's Scoring Process is Suboptimal for his Projected Role
There are far more offensive engines at the collegiate level than there are in the NBA, of course in raw totals but also in viability. Remaining an impact player at the next level is a whole lot easier when you have other paths to success. Jevon Carter blossomed into an offensive engine in his senior season at West Virginia, but he was incredibly inefficient, particularly at the rim, shooting just 44.1%.
His defensive edge is what's kept him in the NBA, while the role inheritance from being overtasked in that senior season, has allowed him to remain a slight threat running PNR on the weakside.
LaBaron Philon was another name in that uber-productive offensive query, who I'll end up ranking higher than consensus relative to where I have Dybantsa because he's exhibited multiple paths to success. Philon played much more off-ball in his freshman season, grading out as a Primary Handler before making the leap to Offensive Engine in 2026.
So Philon's profile marries together an uber-effective offensive engine and an effective off-ball handler who defended much better at lower-usage, all while maintaining a very impressive 2P self-creation load AND efficiency. While he's tested extremely poor in back to back years at the combine and he's incredibly light, I think his strong 2P signal is an indicator that he may have a deceptively strong trunk and the freshman year defense makes me think he could slot in nicely as a screen navigator on defense and thrive in a Deuce McBride/Ajay Mitchell/Payton Pritchard-esque role as an off-ball guard that doesn't bleed TOO much defensive value and strongly compliments lead creators on offense.
This persisting across multiple collegiate seasons is why I'm more confident in my eval of Philon than Dybantsa, but it's also reflective of Philon's enticing duality as a player who can shapeshift himself up OR down the usage chart.
With all that being said, Boozer & Peterson will take their place in the 2 highest echelons of my board, because they were similarly as impressive while exhibiting a more holistic footprint over the game.
Quick Hitters
I've enjoyed searching for anomalous role distributions at particular positions, with maybe my favorite example being Dailyn Swain's primary handler/Interior Creator split.
I was extremely pleased to see Tari Eason pop up as a defensive comp for Allen Graves (and Covington as well).
Ebuka Okorie's similar profiles made me rethink him for a bit as well.
We're at the end of the article and I've only talked about the algorithmic output of the 1st 5 words in this sentence: "...classify prospects' current pre-NBA role, then project their NBA role, impact and playstyle based on their statistical profile and pre-NBA playstyle". This is mainly because I underestimated just how long it would take to fetch the NBA data I wanted to compare profiles historically, though I think not quite having the full model output finished has also afforded me the opportunity to slowly integrate these distributions into how I conceptualize prospects. It WILL be finished though, so be on the look out for Parts 2 (and probably 3) of the expansion of this model.
Create probabilistic role distributions utilizing Archetypoid Analysis t0 models extreme styles to describe playing style/role, not quality (good-vs-bad) or team context. Devise interpretable labels for each archetype.
2. Methodology
Convex membership. Each player-season's α-vector (the persisted distribution) is solved by non-negative least squares with a big-M sum-to-1 augmentation.
Initialization:FurthestSum, then a bounded local-swap that minimizes reconstruction error (the Vinué archetypoid refinement).
Two separate models: offensive features → offensive roles; defensive features → defensive roles.
3. Quantitative measures used
Pruning methodology and more
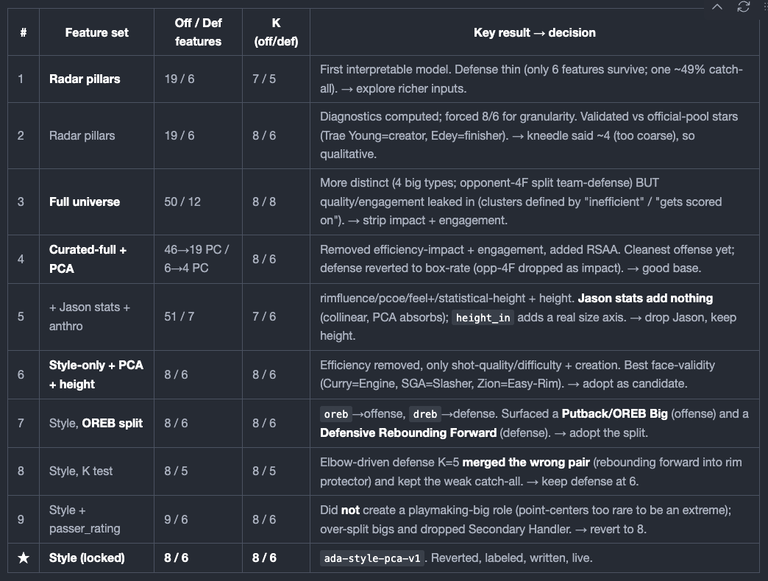
4. Staged model evolution
Decisions I made as I iterated through different features and models
5. Final model
K diagnostics (final feature set):
Offense intra-archetype variance: K7 = 3.36 (min), K8 = 3.49 → method points to 7; RSS 7→8 is a flat plateau (2784→2768). K=8 kept by interpretability.
Defense RSS: K4 = 91,991 → K5 = 22,545 (the cliff) → K6 = 22,152 (plateau) → elbow at 5; K=6 kept because 5 merges the rebounding forward.
Interpretations: The most distinct archetypes are the bigs (Rim Runner 3.57, Hustle Big 3.02) and Primary Rim Protector (3.36). The least distinct are Connective Shooter (1.24) and Interior Creator (1.25) on offense and Low-Activity Helper (0.89, zero strong features, a 3,233-member near-average catch-all) on defense. Low-Foul Big (1.74) is an archetype I didn't want to keep but it was legitimately informative (one strong axis, pf −1.6) .
↩an image generator i made in undergrad that attempted to create novel images then classify them with a separate model
↩for more details on how these statistics were selected & the methodology i used, read the portion at the end of the article
↩a great example of the limitations of even ADA, Lipsey has been perennially one of the best defenders in college basketball but the model doesn't reward the steal rate without rebounding equity or impacting shots at the rim.
I’m a lifelong basketball enthusiast who blends film study and advanced analytics in my independent coverage of basketball and the NBA Draft across Tiktok, Twitter, Youtube, Substack and Instagram. I’ve also covered the Hawks for ~2 years as an accredited digital journalist for Afro News, and I am a member of the Atlanta Hawks’ Creators Collective.
%20(4)-1600x900.png)

























Comments